The most common use cases that we have seen with our Data Prep Early Adopter customers are the following:
- Multi-counterparty trade or position reconciliations
- Multiple internal systems
- Multiple external datasets vs multiple internal source systems
1. Multi-counterparty reconciliation:
A common use case for Data Prep is where a single internal file capturing trades/positions needs to be reconciled against files coming in from multiple counterparties. Typically the counterparty data is captured in different file formats with different layouts. This scenario will require a single Data Prep process to consolidate and normalise your multi-counterparty data and a two-sided generic process, where this is reconciled against your internal data.
The different counterparty files will be fed to a Data Prep process, that will apply mappings and any normalisation required to produce a single combined output data set. See the Data Prep Quick Start Guide for how to configure this. Once that has been set-up, a two sided process can then be created, with your internal file as one Data Input and the Data Prep process acting as the other. The rest of the configuration steps will be as is standard for a two-sided process.
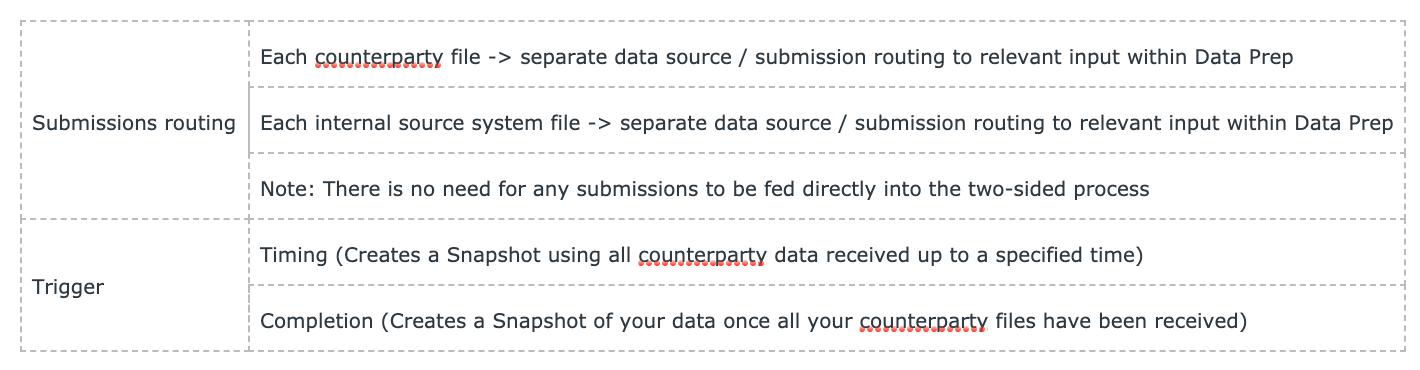
Submissions routing:
Automating such a reconciliation using SFTP will require that the counterparty files are pointed at the Data Prep process, while the internal files are fed into the two-sided process directly. Each counterparty file will require its own data source or submission routing to the relevant input within the Data Prep process; and the internal file will need a separate data source or submission routing pointing to the internal side of the generic two-sided reconciliation.
Triggers:
The Data Prep process will also require a trigger or triggers to automate this part of the flow. Typically either a Timing (that uses all data received up to a specified time) or a Completion trigger (that creates a snapshot of your data once all your counterparty files have been received) would be used here. This will automate the creation of snapshots, which will then be pushed into the two-sided process. The run will be automatically initiated when the two-sided process has both the internal file and the Data Prep snapshot.
The table below outlines what submissions routing and triggers could be used for this use case in order to automate data feeds and snapshot creation:

2. Multiple internal systems
You might want to condense data from multiple internal systems, such as different Order Management Systems and then use that normalised output file to reconcile against your ARM, for example. The setup will require one Data Prep process which will merge the OMS files and one two sided process that will reconcile the OMS normalised output with your ARM data.
The different OMS files will be fed to a Data Prep process that will apply mappings and any normalisation required to produce a single combined output data set. See the Data Prep Quick Start Guide for how to configure this. Once that has been set-up, a two sided process can then be created, with your ARM file as one Data Input and the Data Prep process acting as the other. The rest of the configuration steps will be as is standard for a two-sided process.
Submissions routing:
Automating such a reconciliation using SFTP will require that the OMS files are pointed at the Data Prep process, while the ARM files are fed into the two-sided process directly. Each OMS file will require its own data source or submission routing to the relevant input within the Data Prep process; and the ARM file will need a separate data source or submission routing pointing to the ARM side of the two-sided reconciliation.
Triggers:
The Data Prep process will also require a trigger or triggers to automate this part of the flow. Typically either a Timing (that uses all data received up to a specified time) or a Completion trigger (that creates a snapshot of your data once all your counterparty files have been received) would be used here. This will automate the creation of the Snapshot, which will then be pushed into the two-sided process. The run will be automatically initiated when the two-sided process has both the ARM file and the Data Prep snapshot.
The table below outlines what submissions routing and triggers could be used for this use case in order to automate data feeds and snapshot creation:

3. Multiple external datasets vs multiple internal source systems
There may be scenarios where a reconciliation has multiple inputs on both sides. This is useful if, for example, you are looking to condense multiple counterparty files and reconcile the output against multiple internal source systems. The setup for such a reconciliation will require two Data Prep processes that will be configured to consolidate and normalise your counterparty and internal files. See the Data Prep Quick Start Guide for how to configure the two Data Prep processes. Once these are in place, you will then need to create a generic two sided process, the inputs of which will be the the two Data Prep processes created earlier. After the two sided process is fully configured, snapshots from each Data Prep process would then be fed into the process for reconciliation.
Submissions routing:
Submissions for this process will be directed to the Data Prep processes, with no need for any files to be fed directly into the two-sided process. Once the two-sided process receives snapshots from both sides, a run will automatically be triggered.
Trigger:
The Data Prep process will also require a trigger or triggers to automate this part of the flow. Typically either a Timing (that uses all data received up to a specified time) or a Completion trigger (that creates a snapshot of your counterparty and internal data once all your files have been received) would be used here. This will automate the creation of the Snapshot, which will then be pushed into the two-sided process. The run will be automatically initiated when the two-sided process has got Snapshots from both sides.