Introduction
A generic single-sided process is a process distinguished by having only one Data Input. You will find that the set-up steps for creating a single-sided process are mostly aligned with the standard configuration steps you would follow when creating a generic two-sided process. However, there are a couple of distinctions, which are detailed in the Building a single-sided process section below.
The potential usage cases for single-sided processes are varied and include true reconciliation, data enrichment, data clean-up, and more. Below you will find some examples of the ways you can leverage this useful functionality.
Building a single-sided process
Select the Process tab at the top of the screen and then Create Process.
This will take you to the following dialog box. Selecting Type will open up a drop-down menu, with the second option being a Generic single-sided process.
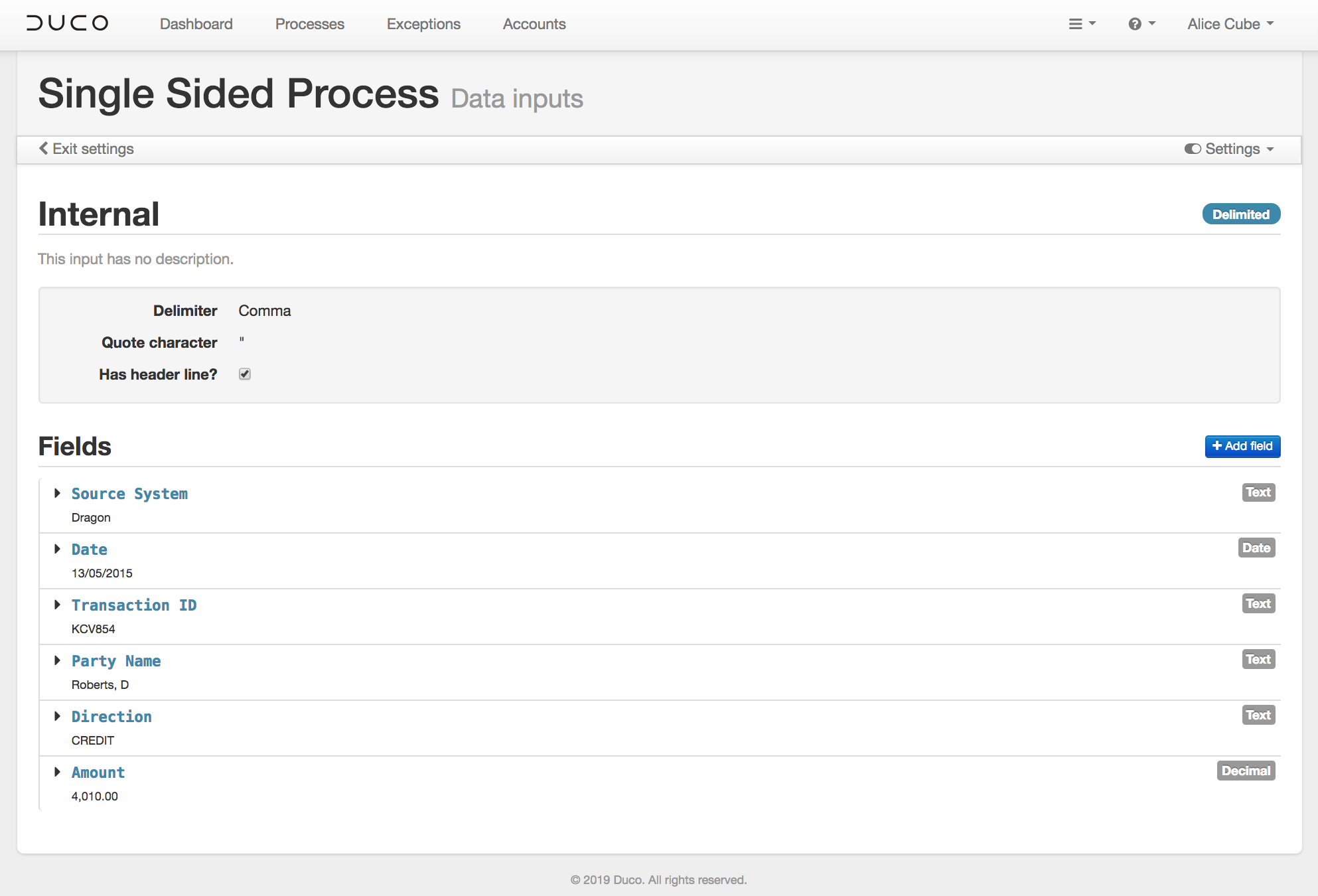
The configuration of a single-sided process is distinguished from that of a generic two-sided process in two ways. Firstly, the Data Inputs screen will only allow for the upload of a single sample input.
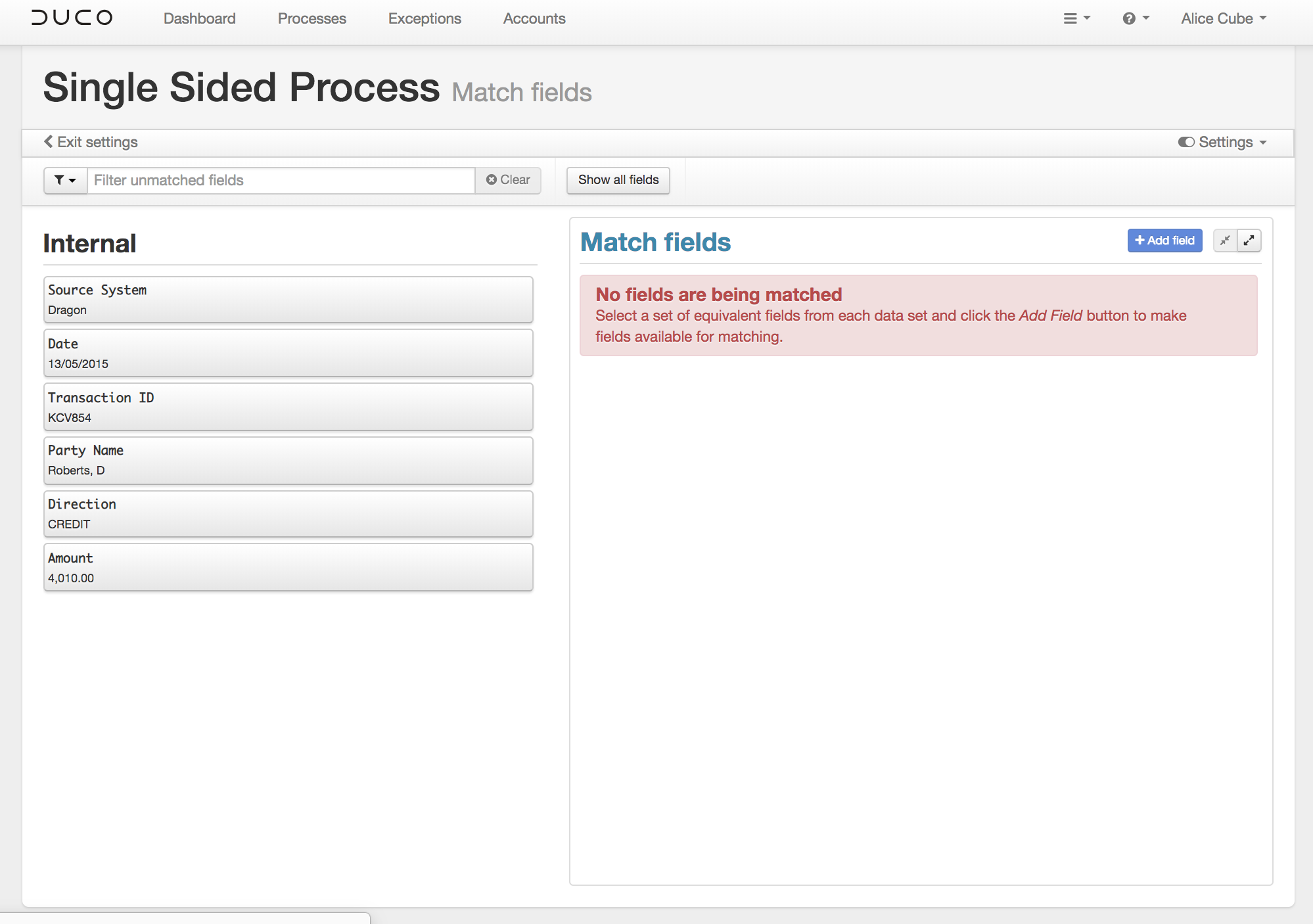
The second difference is found on the Match Fields screen. For a single-sided reconciliation the matching will be happening within the individual fields of the input that are specified by the user. There is no opposing side that the match field has to be paired with.
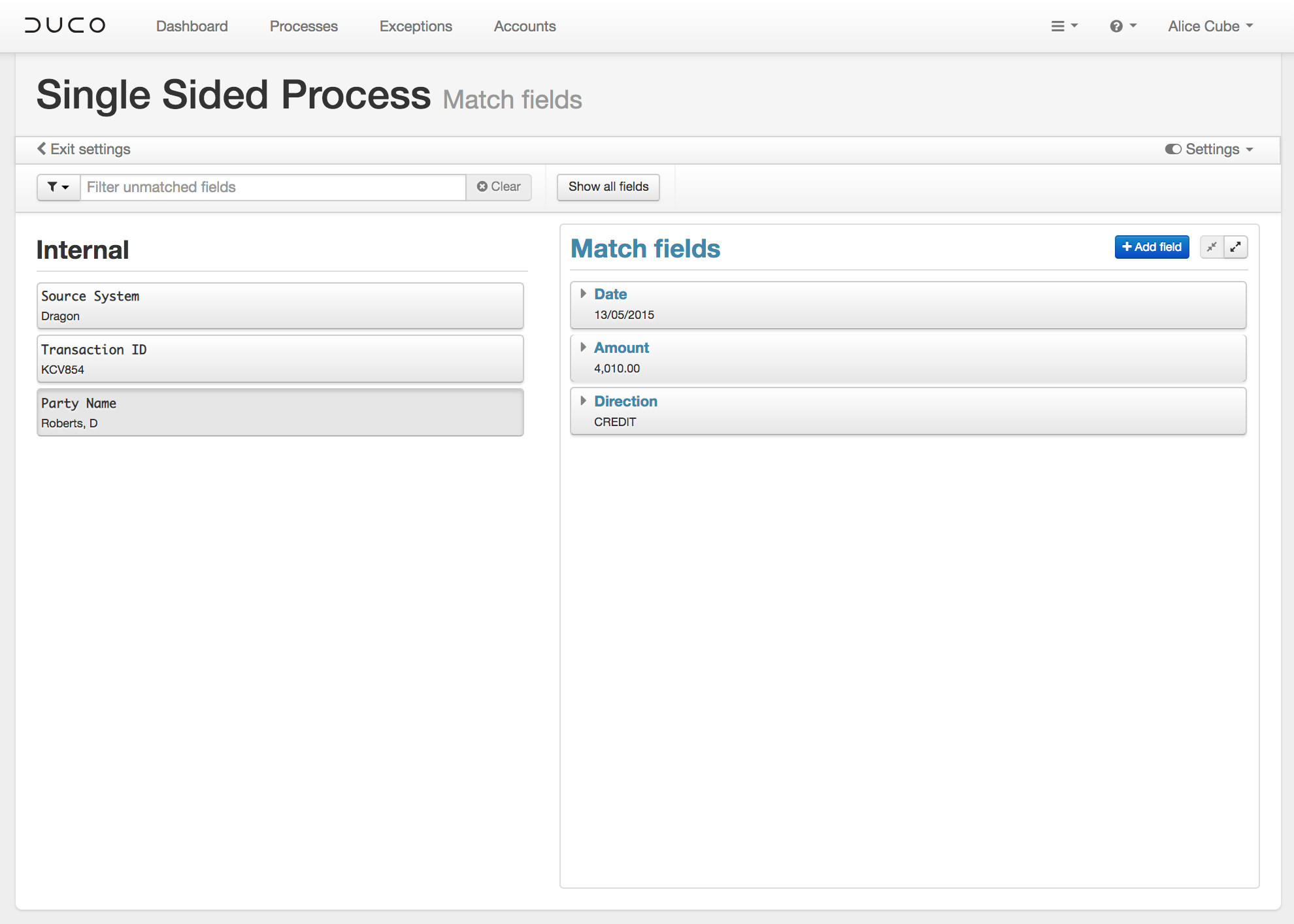
Aside from these two differences, any additional configuration steps, such as adding rules or roll-ups, can be made in the same way as a generic two-sided process. Similarly, the results of a run will be displayed just as those of a two-sided process.
Use cases
The following are examples of some of the ways a single-sided process can be leveraged.
Data Enrichment & Transformation
Single-sided processes can be utilized for the purpose of data enrichment and/or transformation. A basic example of this could be where NRL is used to populate values from a reference table. This may be a way to pull additional information into the process that is not present in the original input files, or you may want to switch out some of the original values from the input with correlating values that are held in a reference file.
Example 1 - Transformation
Let’s say that you have a broker file that uses their internal account identifier. It may be desirable to have this value switched out in favour of your own internal ID. Through a combination of NRL and a reference table, we could achieve this transformation:
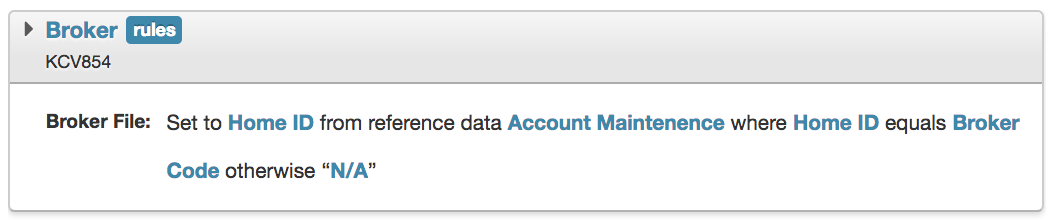
Example 2 - Enrichment
One way of achieving enrichment is through the use of Calculated Fields. In this scenario we have a Margin Balance file that we want to enhance by including a field that captures Total Equity. To do this we could add into the process a calculated result that delivers this value:

Data clean-up
You may find that outputs from some of your internal systems are not always delivered in the most digestible format. A single-sided process can offer a method of ‘cleaning-up’ up these files to make them easier for your teams to analyze.
Example 1
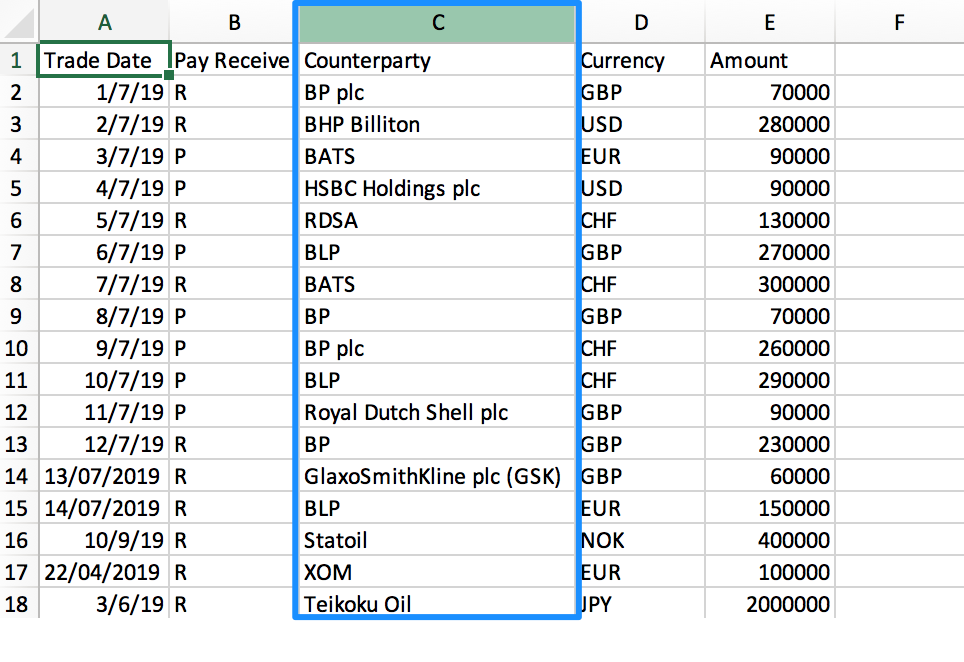
For example, in this payments file we have inconsistent data within a Counterparty field, where mixture of identifier codes and full counterparty names are being used.
Here we could leverage NRL and a reference table to normalise this column, having it transformed to consistently display either the counterparty code or the counterparty name, depending on which is preferable.
Example 2
Another example could be where a file contains values that you would prefer to have segregated into separate columns.
In this instance we could add the Amount field as a matching field twice.
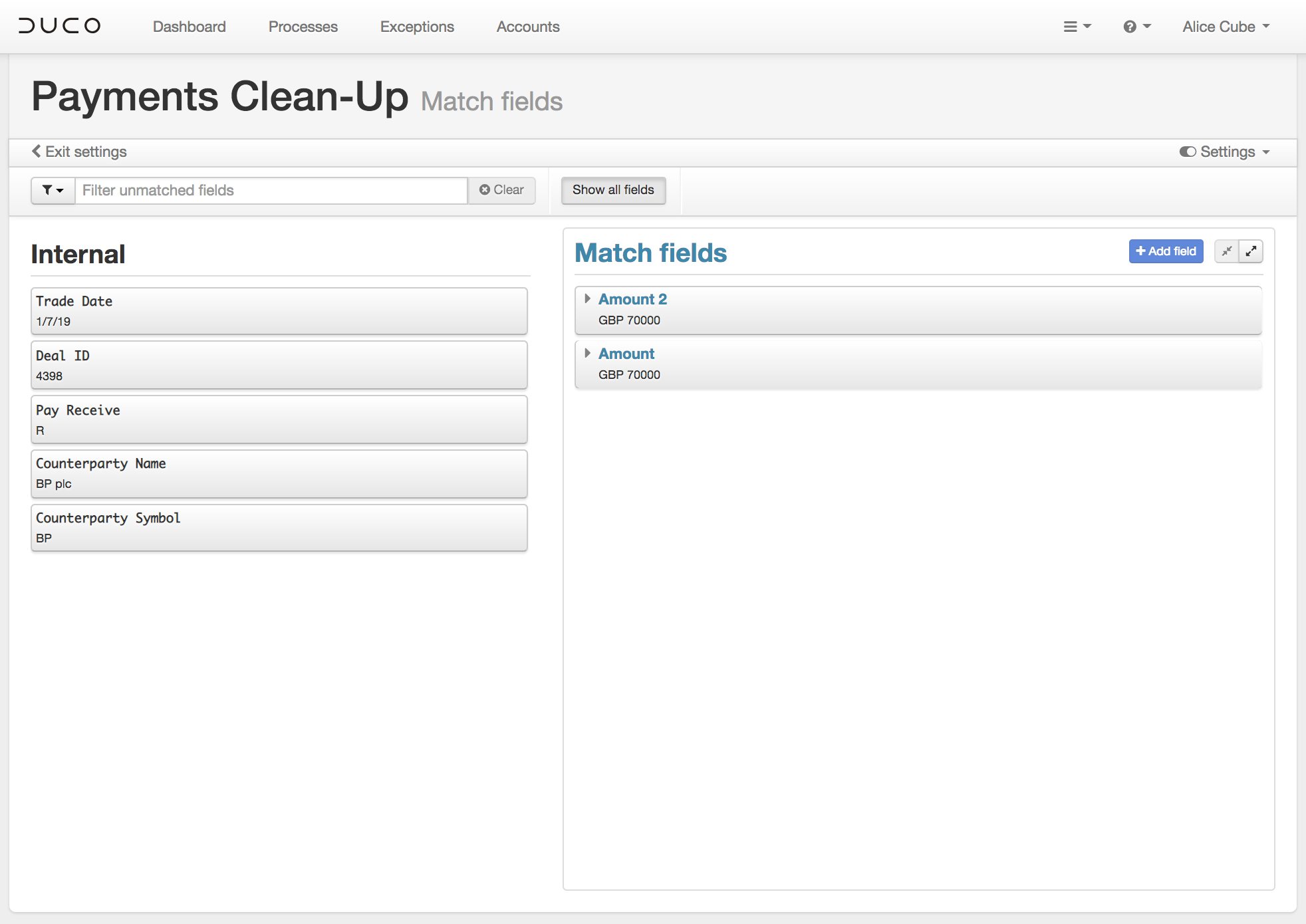
And then use NRL to extract the relevant segment of the data for each of the new fields.


If now include the other fields from the file and run the process, it is then possible to export the cleaned-up file with the transformed data.
Debits and Credits
A single-sided process can offer a solution for a balance sheet reconciliation. Let’s say, for example, a double-entry accounting method is being used, meaning every debit and credit is expected to match off and net out.
In that scenario I could use, for example, Amount, Currency, Date and Entity as my match fields:
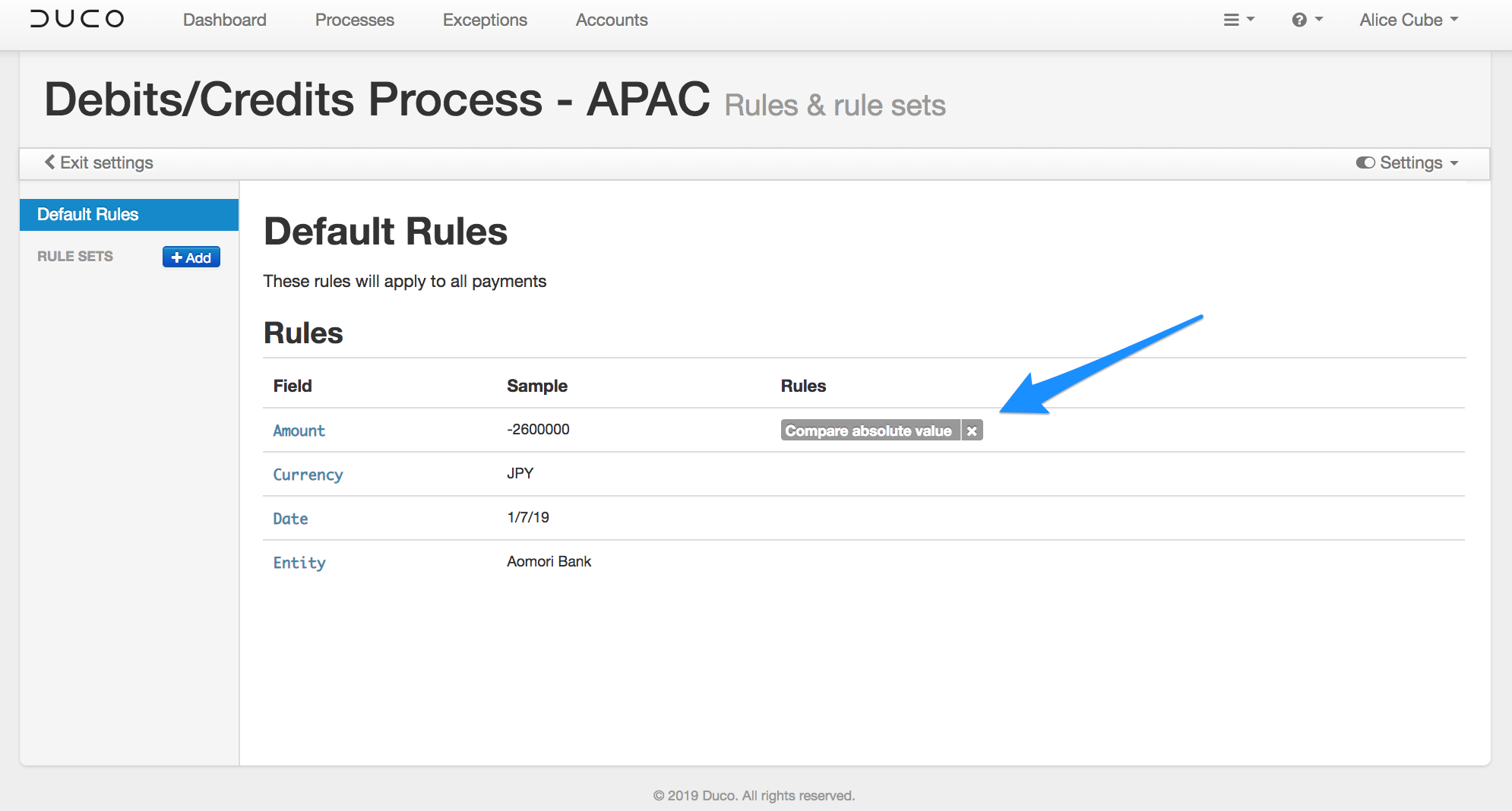
This process might also require either a Compare absolute value rule to allow the positive and negative values to be matched.
Or we could leverage an NRL rule to make both values positive.

Here's an example of the results of such a process:
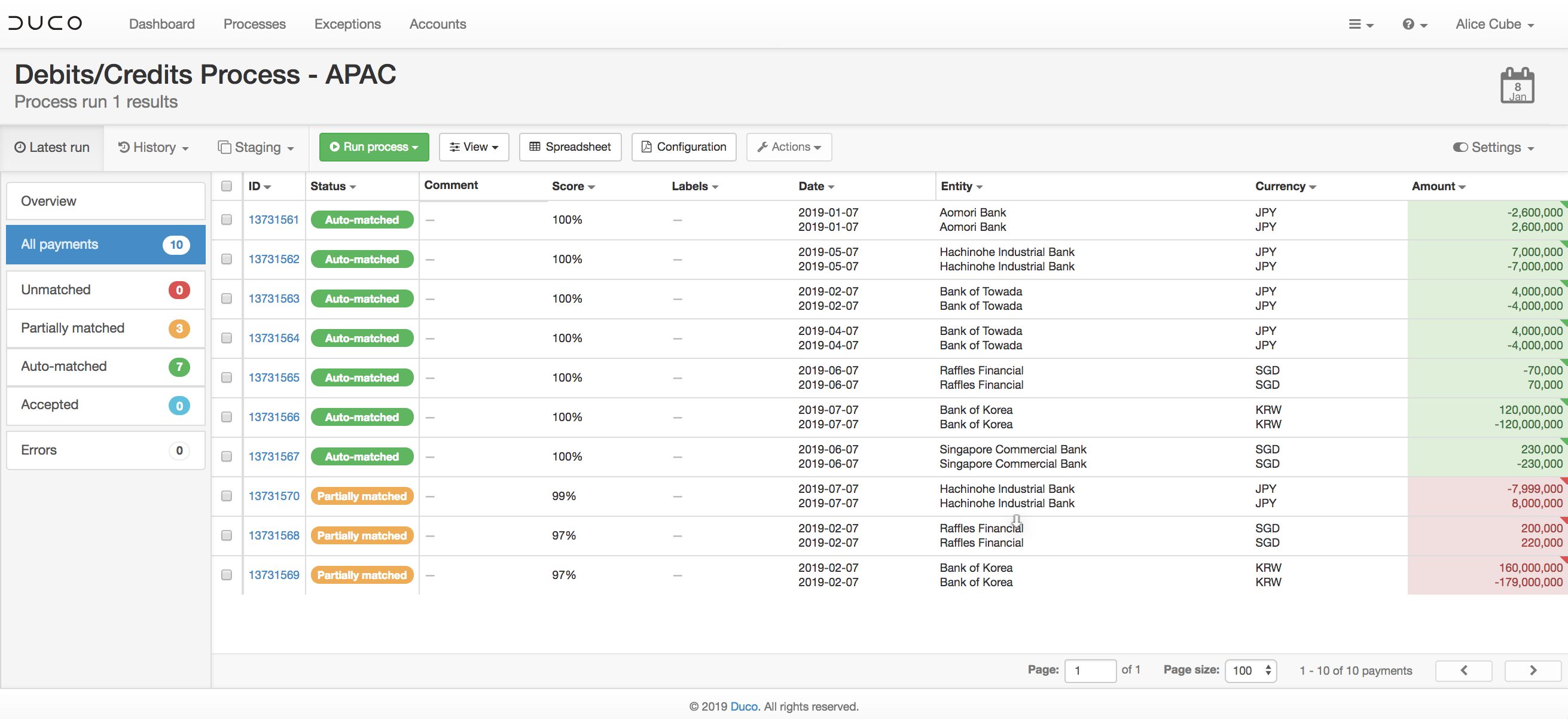
In a more complex scenario where the values differ on one side owing to the inclusion of fees, Duco's NRL can be leveraged to normalise out the values and break the fees out into a separate field. Or the reverse is also possible, where a fee is brought into a value, again by leveraging NRL.

Position Limits
A single-sided process can be a means for comparing positions held against position limits that have to be adhered to. Let’s say for example you have an input file where you have futures contracts listed out individually, but require a view of the net positions aggregated by date and contract code, which can then be compared against the relevant position limit.

In a scenario where the position limits are held in a separate file, this can be included in the process as a reference table. Using NRL, we could then create a field that calculated the percentage of the limit that each position constituted. By then applying roll-ups, we could then see where the position limits had been exceeded.
The results could then be sorted in descending order to allow you to address the largest breaches of the limits first. It would also be possible to leverage Workflow rules, in order to automatically close exceptions where the rolled-up positions were within the permissible limit.
Duplication Identification
By enabling record tracking on a single-sided process, it is possible to quickly identify duplicate entries in a file.
This can be especially useful for static data files. You may find in that scenario enabling the Fuzzy Match rule can be of additional assistance, as it will identify and pair duplicate text items that are probable pairs but not quite identical, and hence do not fall out automatically as duplicates.
Data Validation
A single-sided process can be used to verify if data in a data set conforms to specific ranges/values.
Fee comparison
A single-sided process can be leveraged to perform a consistency check for fees being charged by different offices. Where the currency is the same, a simple comparison is straightforward to configure. Where the fees are made in differing local currencies, an NRL rule pointed to an FX reference table could be utlised to normalise out the values.